
Практикам по оптимизации полезно знать, как работают просмотр, индексирование и ранжирование, поскольку это помогает им определить, какие действия необходимо предпринять для достижения своих целей. В этом разделе в основном описываются способы работы Google, Yahoo! и Microsoft, но, возможно, он неприменим для других популярных поисковых движков, таких как Baidu (Китай) и Naver (Корея).
Поисковые движки имеют несколько основных целей и функций. В их число входят следующие:
• просмотр и индексирование миллиардов документов (страниц и файлов), доступных в Интернете;
• ответы на запросы пользователей (с выдачей списков релевантных страниц).
Мы рассмотрим основы этих функций с нетехнической точки зрения.
Просмотр и индексирование
Представьте себе, что Интернет – это сеть станций в подземке большого города. Каждая станция – уникальный документ (обычно web-страница, но иногда это файл формата PDF, JPEG или другого формата). Поисковому движку нужен способ «проползти» по всему городу и найти по дороге все станции, поэтому он использует самый лучший из имеющихся маршрутов: ссылки между web-страницами (рис. 2.11).
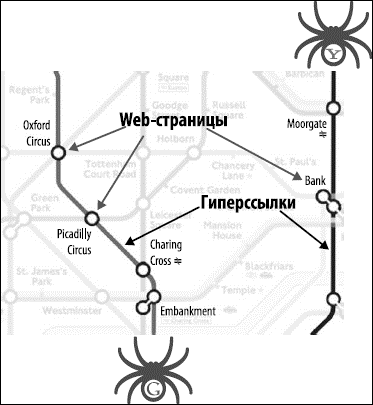
Рис. 2.11. Лондонская подземка здесь используется как аналогия для обследования пауком.
На нашем рисунке такие станции, как Embankment, Picadilly Circus и Moorgate, являются страницами, а соединяющие их линии представляют ссылки с этих страниц на другие страницы Интернета. Как только Google (нарисован внизу) доберется до Embankment, он увидит ссылки на Charing Cross, Westminster и Temple и сможет получить доступ к любой из этих страниц.
Структура ссылок сети Интернета связывает между собой все страницы, которые были сделаны публичными в результате установления ссылок на них. При помощи ссылок автоматизированные роботы поисковых движков, называемые «пауками» (именно поэтому они изображены в таком виде), могут добраться до многих миллиардов взаимосвязанных документов.
Когда поисковые движки находят эти страницы, их следующая задача состоит в том, чтобы сделать анализ кода этих страниц и сохранить элементы этих страниц в огромных массивах жестких дисков (чтобы при необходимости их можно было извлечь для ответа на запрос). Чтобы справиться с этой монументальной задачей по хранению миллиардов страниц (к которым можно получить доступ в доли секунды), поисковые движки создают огромные центры обработки данных.
Одна из ключевых концепций создания поискового движка – это решить, откуда начать поиск по сети. Несмотря на то, что теоретически начать можно из многих мест, в идеале следует начинать с доверенного набора web-сайтов. Фактором оценки доверия к вашему сайту можно считать расстояние (в количестве кликов) между вашим сайтом и наиболее доверенными сайтами. Повысить уровень доверия к Вашему сайту можно путем улучшения поведенческого фактора, например заказав у нас контекстную рекламу.
Источник: IMARKETING — «Искусство продвижения сайтов».